Understanding TOOD: Task-aligned One-stage Object Detection
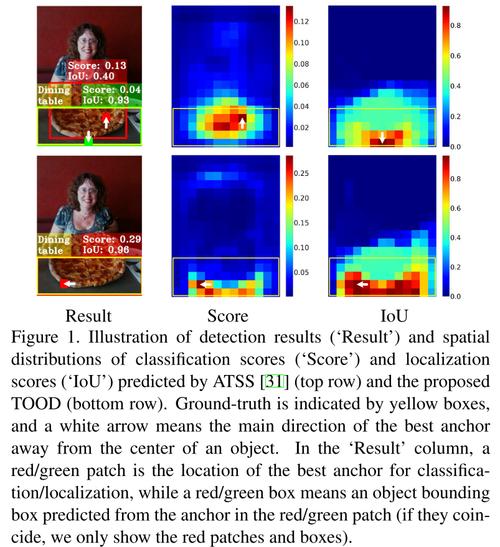
Have you ever wondered how a computer can accurately detect and classify objects in an image? One of the key technologies behind this is object detection, and one of the most innovative approaches in this field is the Task-aligned One-stage Object Detection (TOOD). In this article, we will delve into the intricacies of TOOD, exploring its architecture, working principles, and its impact on the field of computer vision.
Addressing the Challenges of Object Detection
Object detection involves two primary tasks: classification and localization. Classification is about identifying what an object is, while localization is about determining where it is in the image. However, these two tasks often work independently, leading to inconsistencies in predictions. For instance, a high classification score might not correspond to an accurately localized object, and vice versa. This is where TOOD steps in, aiming to align these two tasks for more accurate and reliable object detection.
The TOOD Architecture

TOOD is designed as a one-stage object detection system, which means it performs both classification and localization in a single pass. The core of its architecture is the Task-aligned Head (T-Head), which consists of two main components: Task-aligned Predictors (TAP) and Task-interactive Features.
| Component | Description |
|---|---|
| Task-aligned Predictors (TAP) | These predictors are responsible for generating predictions for both classification and localization tasks. They take the task-interactive features as input and produce the corresponding predictions. |
| Task-interactive Features | This component extracts features that are relevant to both classification and localization tasks. It aims to bridge the gap between the two tasks by providing a common representation of the object. |
Task Alignment Learning (TAL)
While T-Head addresses the issue of task alignment by providing a common representation of the object, Task Alignment Learning (TAL) takes it a step further by explicitly aligning the two tasks. TAL achieves this by designing a sample assignment strategy and a task-aligned loss function.
| Component | Description |
|---|---|
| Sample Assignment Strategy | This strategy assigns samples to anchors based on their relevance to both classification and localization tasks. It ensures that the samples are well-represented for both tasks, leading to better alignment. |
| Task-aligned Loss | This loss function encourages the model to align the predictions of the two tasks. It does so by minimizing the difference between the predictions of the two tasks for each sample. |
Performance and Impact
TOOD has demonstrated impressive performance on various benchmark datasets, such as MS-CoCO. In fact, it has achieved state-of-the-art results in terms of accuracy and efficiency. This has made TOOD a popular choice for researchers and developers in the field of computer vision.
TOOD’s innovative approach to task alignment has not only improved the accuracy of object detection but has also paved the way for new research directions. By addressing the challenges of task alignment, TOOD has opened up new possibilities for developing more advanced and efficient object detection systems.
Conclusion
TOOD is a groundbreaking approach to object detection that addresses the challenges of task alignment. By combining the Task-aligned Head and Task Alignment Learning, TOOD has demonstrated impressive performance on various benchmark datasets. As the field of computer vision continues to evolve, TOOD and similar approaches are likely to play a crucial role in shaping the future of object detection.





